In an ideal world, the source system of your data warehouse has the exact information that you need to populate all of the fields in your dimensions. In a less than ideal world (also known as the real world), we need to cobble pieces of data together. You may come across one scenario where all of your dimension and fact information is in one large table. How do we handle this ETL in SQL Server Integration Services?
It is possible to load new records into your dimensions while loading your fact. One way would be to use a Lookup transformation to check for existence, and if the business key doesn't yet exist, insert that value, return the surrogate key, and go along your merry way. On the other hand, if you need to use those dimensions for other fact tables, you may decide to load only your dimensions first.
To load all dimensions from one table, we can utilize the Aggregate transformation in SSIS, which provides the capability to perform aggregations on columns in your data flow. The aggregations that are available to you include: Count, Count distinct, Sum, Average, Minimum, and Maximum. You also include a column to group the data. For the output that you're setting up, you can add as many columns to aggregate or group by that you need. For those of you familiar with T-SQL, this concept should be very similar to the GROUP BY clause.
When we're working with aggregations in SSIS, there are a few other things we should mention. The aggregate transformation will not pass through all input columns, only the columns that you specify in your settings. You can set comparison flags on your grouping columns on how to group the data together. I also use the "Ignore case" option to help get a list of case insensitive distinct values from the column.
Initially opening up the Aggregate transformation allows you to set up the columns you want aggregated and what you want to group by. In this scenario, we will use the Group By function for each column to get a distinct list of values; however, if we put all of them on this screen, we will still end up with duplicate values. Instead, we want to create multiple outputs that each contain a single Group By on the appropriate column.
There's a sneaky little button at the top of the designer window that toggles between Advanced and Basic modes. It defaults to Basic, which is why you only see one list right now. Push that button to toggle to Advanced and create a different output for each dimension you need to populate. Once you have a different output, you can perform a lookup against that dimension and only insert records that do not exist. We end up with a package that looks similar to this to load all of our dimensions:
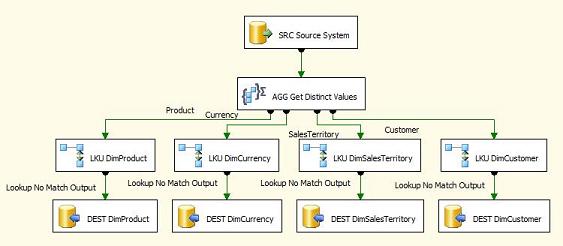
The aggregate transformation has a little bit of a bad reputation, as well it should. It is an asynchronous component, so it creates a new buffer set when it runs, uses a huge amount of memory, and slows down your package execution time. See Kirk's great article about performance tuning SSIS (the aggregate transformation notes are applicable to both 2005 and 2008) for more information: http://www.simple-talk.com/sql/sql-server-2005/sql-server-2005-ssis-tuning-the-dataflow-task/.
This method may not be the best for your situation. It will load the source data twice and doesn’t take into account any slowly changing attributes. This should only be used if the situation calls for it. Hopefully, this will help you if you do fall into that situation!
Version used: SSIS 2008 SP1
Comments
O had to load 4M rows in less than minute with entire ETL. There were like 5 dimensions & 1 fact.
But I tried following things to get it up to the mark. There were other things as well I tried.
1. Execute SSIS packages from different server than that of SQL Server.
2. Restrict SQL memory to little on this SSIS box.
Maybe could be interesting
http://pedrocgd.blogspot.com/2007/05/ssis-populating-dimension_28.html
But using a mirror or a staging database could be more usefull.
Regards,
Pedro